2. 栈和寄存器CPU架构,以及Dalvik虚拟机
虚拟机(VM)是在本地操作系统上的一层模拟真实机器的抽象。这里要说的是进程虚拟机而不是系统虚拟机。1 这种虚拟机可以在不同的机器架构和操作系统上保持一个统一的平台。Java和Python的解释器就是这种,代码都会被编译成为VM自己的bytecode。微软的.Net也是如此,代码都是编译成为中间层的语言CLR(Common Language Runtime)。
那么虚拟机应该都实现一些什么功能么?它应该模拟真实的CPU的各项操作,以及完成以下的功能:
- 翻译源代码到VM专用的bytecode。
- 用于存储指令、操作数(也就是指令操作的对象)的数据结构。
- 调用栈,用来支持函数的调用。
- 指令指针(IP),用于定位下一个将要执行的指令。
- 一个虚拟的CPU,进行指令的调用,包括
- 获得下一条指令(IP所指的地方)
- 解析操作数
- 执行指令
目前有两种实现VM的方法:基于栈和基于寄存器。栈VM的例子包括Java虚拟机、.Net CLR。这也是被广泛采用的一种设计。寄存器VM的例子包括Lua VM还有Dalvik VM(这个马上我们就会细说)。两者的区别在于存储、读取操作数的方法不同。
2.1. 栈虚拟机
栈虚拟机实现了我们之前说过的一个VM应该实现的功能,只不过存储操作数的内存结构是一个栈。操作过程一般都是先从栈中弹出数据、处理数据最后再压栈回去的LIFO(Last In First Out)模式。在栈虚拟机中,两数求和的过程一般都是这样(其中20、7、result都是操作数):
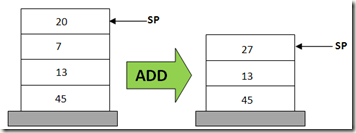
POP 20 POP 7 ADD 20, 7, result PUSH result
由于需要PUSH和POP操作,加法操作总共需要四条指令。栈模型的优点在于操作数都是被栈指针隐式的指定的(图中的SP)。虚拟机是不需要显式指定操作数的位置的,因为通过SP(POP操作)就可以获得下一个操作数。在栈虚拟机中,所有的代数、逻辑运算都是通过PUSH和POP栈中的操作数和结果来实现的。
2.2. 寄存器虚拟机
这种虚拟机的操作数都是存储在CPU的寄存器中的。不再需要PUSH、POP的操作,但是你需要指定运算的操作数的位置(具体是在哪个寄存器里)。就是说,操作数的位置都是需要在指令中显式的指定的。不像栈虚拟机,反正下一个操作数就是SP所指的地方。比如,上面的加法操作在寄存器虚拟机里会是这样:
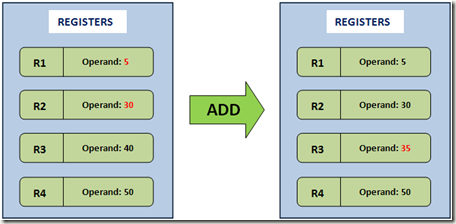
ADD R1, R2, R3 ; # Add contents of R1 and R2, store result in R3
上面我说了,不许要POP和PUSH操作,所以加法只需要一行指令。但是比起栈的方法,我们就需要指明三个操作数的位置分别在R1、R2、R3寄存器上。优点就是没有出栈、压栈的多余损耗了,所以调用指令上就更快。
另一个优势就是它允许一些栈虚拟机中无法实现的优化技巧。一个例子就是如果代码中有很多相同的减法操作,寄存器VM就可以只计算一次,然后把结果保存在一个寄存器里,等将来又出现相同代码的时候就可以直接取出来这个结果,就省下来重新计算一遍的时间。
缺点就是寄存器VM的指令比栈VM的指令长一点,因为需要指定操作数位置。栈VM因为有SP默认指定位置,指令就可以更短点,寄存器VM的指令需要包括操作数的位置、存储结果的位置,指令相比就要长一点。
我读过的一篇文章(链接 ),包括了解释和一个简单的c实现的寄存器VM。如果你对实现VM和解释器比较感兴趣,可以去看一下ANTLR创始人写的书,《Language Implementation Patterns: Create your own domain-specific and general programming languages》。
2.3. DALVIK虚拟机
它是Google为Android写的,用来作为Android设备的Java解释器2。底层的Linux内核都是每个进程创建一个VM,所以是进程VM。每个进程都通过一个独立的DALVIK虚拟机运行。可以减少因为一个VM崩溃造成多个应用都退出的概率。Dalvik是个寄存器虚拟机,而且不同于标准Java bytecode(在栈实现的JVM上使用8bit的栈指令),它用的是16bit的指令集。Dalvik的寄存器都是需要4bit来指定的位置的。
要是我们深入一点,看以下每个进程都获得一个VM是如何实现的,我们就得从头开始…从Linux内核启动的那一刻开始。
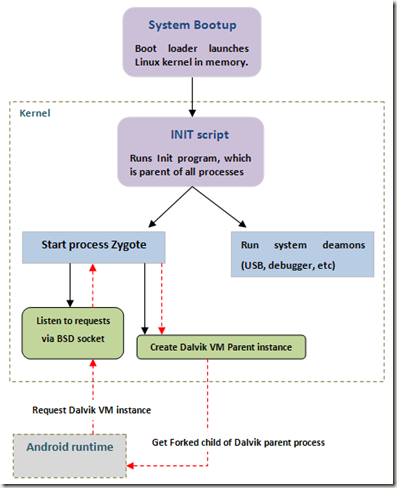
系统启动时候,bootloader会将内核载入内存,初始化系统的参数。之后:
- 内核启动init程序,这也是所有系统中进程的父进程。
- init程序会开始启动各种系统的守护进程,还有十分重要的‘Zygote’服务。
- Zygote进程会创建一个Dalvik实例,作为所有其他Dalvik虚拟机的父进程。
- 之后Zygote会打开一个socket端口,监听任何请求。
- 一旦收到任何请求,Zygote会fork一个新的进程,然后传给请求的应用。
这也就是DalvikVM如何在Android中创建和使用的。
回到VM的主题,Dalvik和JVM不同点在于他运行的是Dalvik bytecode,而不是传统的Java bytecode。在Java编译器和Dalvik之间会有一个中间过程,将Java的bytecode翻译成为Dalvik的bytecode。实现这个过程的是DEX编译器。具体不同可见下图:
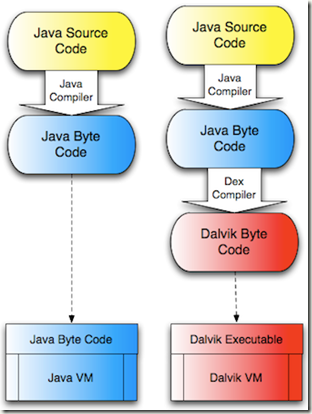
DEX将java的.class文件翻译成为.dex文件,dex文件体积更小,也正对Dalvik进行了优化。
2.4. 结束
具体两种VM孰优孰劣尚无定论。目前争议较多,也是一个有意思的研究领域。有一篇很有意思的论文 ,作者将JVM换成了寄存器实现,获得了很明显的性能提升。希望我在这里解释清楚了栈虚拟机和寄存器虚拟机的区别,以及Dalvik VM的一些细节。欢迎各位读者针对文中内容的反馈和提问。
Footnotes:
关于解释器、编译器、CPU、物理机器的纠结,可以看下王垠大大的说明,地址忘了。